
Data Normalization Overview
Once you have generated the fractal data, the Fractal Science Kit fractal generator needs to prepare the data for display. This is called normalization. Normalization is the process of rescaling or redistributing the sample data to improve the visual display. Normalization is controlled using the normalization properties on several of the properties pages. While these pages differ slightly depending on the type of data being normalized, they are similar enough to describe together.
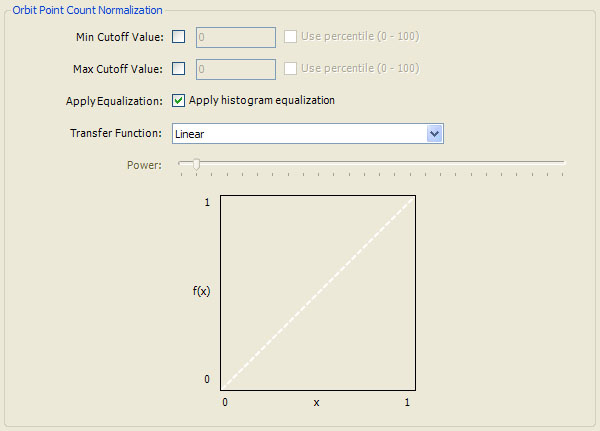
There are 3 steps applied to the sample data values during normalization:
- Contrast Stretching
- Histogram Equalization
- Transfer Function
Contrast Stretching rescales the sample data values into the range 0 to 1. We apply a simple linear transformation resulting in values from 0 to 1, which are easily mapped to color values. During this step you can specify minimum and maximum cutoff values, and the sample data values outside this range are set to 0 or 1, respectively. This can be used to eliminate outlier data values or to limit the values to a specific range, as required.
The minimum and maximum cutoff values are given by Min Cutoff Value and Max Cutoff Value, respectively. These can be given as actual data values or as a percentile (0 to 100) of the total data. For example, a Max Cutoff Value percentile value of 98 would compute the value P such that 98% of the data is less than P, and map all data greater than P to 1. To use percentile values for either cutoff value, check the Use percentile (0 - 100) checkbox next to the cutoff value.
Histogram Equalization redistributes the sample data in such a way as to evenly spread the values over the 0 to 1 range. This allows efficient use of color resources. Data whose values are concentrated in certain areas will benefit the most. This step is optional. Check the Apply Equalization checkbox to activate this step.
Finally, a Transfer Function is applied to the data which can be used to accentuate one area within the data while minimizing another, as required. See Transfer Function for details.
The Transfer Function can be applied to the sample data with or without Histogram Equalization. If Histogram Equalization is off, the Transfer Function can be used as an alternate method of data redistribution. If Histogram Equalization is on, the Transfer Function can be used to skew the data based on the function's shape and Power, yielding many interesting results.
Mandelbrot Data Normalization
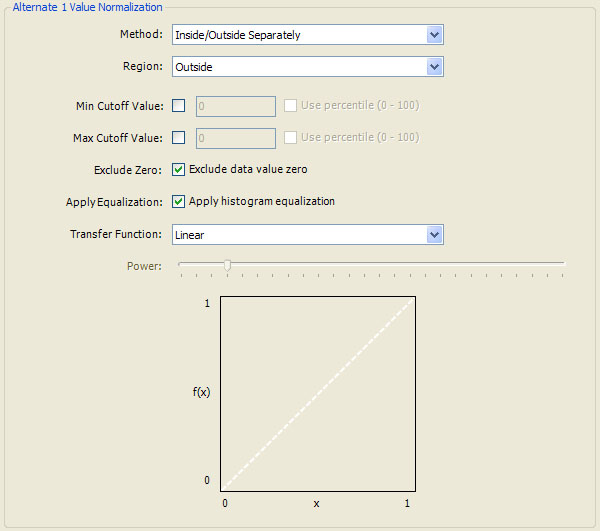
When normalizing Mandelbrot fractal samples, there are several additional controls that are not available when normalizing Orbital fractal samples. Mandelbrot samples can be categorized by whether or not the associated orbit diverged (or converged if the fractal type is Convergent). If the orbit diverged (or converged), the sample is said to be outside the Mandelbrot set. Otherwise, it is said to be inside the set. Normalization can be applied to the sample data using 2 different methods: Inside/Outside Together or Inside/Outside Separately. The 1st method normalizes all the sample values in a single group. The 2nd method normalizes the inside samples separately from the outside samples. In this case, each of the 2 sets has a different set of normalization control parameters.
The Method property is used to choose the normalization method and can be set to Inside/Outside Together or Inside/Outside Separately. If you set the Method to Inside/Outside Separately, the Region property is enabled to allow you to choose which set of normalization control parameters (Inside or Outside) to view/edit.
Finally, the data associated with a Mandelbrot fractal can include samples that are not initialized. To include these uninitialized samples in the normalization process could skew the results. In order to prevent this, an option to Exclude data value zero is included on the normalization properties pages associated with Mandelbrot fractals. If the option is checked, any sample with data value equal to 0 is not passed to Histogram Equalization.
Normalizing Discrete Data
Some fractal data are integer values and the normalization method is handled using a different strategy. First, a minimum value (MinValue) and maximum value (MaxValue) is computed, such that each data value is greater than or equal to MinValue and less than or equal to MaxValue. Next we set Count to the number of discrete values; i.e., MaxValue-MinValue+1. Then we divide the interval from 0 to 1 into Count intervals, and map each data value to the value associated with the beginning of the associated interval, resulting in values from 0 to (MaxValue-MinValue)/Count. For example, if the data values are one of the values 0, 1, 2, or 3, we set MinValue=0, MaxValue=3, and Count=4. Then we map the values 0, 1, 2, and 3, to normalized values of 0.0, 0.25, 0.5, and 0.75. In this way the discrete values are distributed evenly across the range 0 to 1.